一种基于CNN的手写中文文本识别方法与流程
本发明涉及计算机图像处理领域,尤其涉及一种基于cnn(卷积神经网络)的手写中文文本识别方法。
背景技术:
手写中文识别是计算机图像和视觉研究领域的热点之一,在识别历史文档,邮件分类,手写笔记的转录等方面都得到了广泛地应用。尽管在过去的几十年中,国内外学者已经在该领域作了大量研究,但仍然有许多问题没有得到有效解决。手写中文识别的主要困难来自中文结构复杂,字符种类多,数据大,各人风格不同,手写失真等。在某些情况下,相似中文之间的无约束手写样本的差异可能非常小,例如字符“天”,“夫”和“夭”,“已”,“己”和“巳”,“目”,“白”和“自”等,使得识别任务更加具有挑战性。
到目前为止,各国科研人员在手写中文识别领域已经进行了半个多世纪的研究,提出了许多离线识别方法来实现手写中文文本的机器识别,其中,以基于修改的二次判别函数(mqdf)[1]的方法最具代表性。此外,一些传统方法(如修改的二次判别函数mqdf、判别学习型二次判别函数dlqdf),对手写中文识别数据库casia-hwdb取得了较好的识别效果,但识别准确率仍然低于93%,与人类表现尚有一定差距。
近年来,随着计算机硬件的发展和大量的训练数据集的建立,使得基于神经网络识别手写中文文本成为可能。lecun在20世纪90年代提出了cnn来实现字符的机器识别,受到了广泛关注;随着近年来深度学习的兴起,cnn为手写中文识别带来了新的突破性技术,大大缩小了计算机与人类表现之间的差距。
目前,国内外学者已经利用更深层次的体系结构对cnn作了扩展,并采用更好的训练技术(如dropout正规化方法)[2],以及更好的非线性激活功能(如relu线性整流函数)[3],成功解决了众多计算机视觉和模式识别领域存在的问题,取得了比较理想的实现效果,例如:在2013年举办的icdar(文档分析与识别国际会议)[4]上在线和离线中文手写中文识别竞赛中,富士通团队在离线hccr(手写中文识别)竞赛中获得第一名,准确率达到94.77%。2014年,吴等人基于4个经过改编训练的松弛卷积神经网络(atr-cnn),将手写中文识别的准确度提高到了96.06%。
但是,现有技术一些较高的识别准确率都只是基于单个中文的识别,而在实际应用方面大多数情况都是基于文本的识别,因此从实际应用角度出发,需要在手写中文文本识别上获得较高的准确率。此外,通过加深网络层次与复杂化网络结构来提高识别准确率,会很大程度地增加参数总数,不利于实际应用。
技术实现要素:
本发明提供了一种基于cnn的手写中文文本识别方法,本发明解决了传统手写中文识别准确率较低的问题,并将单个手写中文识别与文字分割算法结合起来,实现了手写中文文本的自动识别,详见下文描述:
一种基于cnn的手写中文文本识别方法,所述方法将单个手写中文识别与文字分割算法结合起来,实现了手写中文文本的自动识别,所述方法包括以下步骤:
对文本图片进行灰度化、二值化处理,再利用直方图投影对中文文本进行分割;先通过横向扫描分割出单行文字,再利用纵向扫描分割出单个文字;
对单个中文图片进行扫描处理,对中文进行正射纠正,并使其位于图片中间位置,上下左右各留出10个空白像素;
基于tensorflow框架构造一个包括:4个卷积层、4个池化层和2个全连接层的卷积神经网络,利用训练集进行训练;输入待测图片,根据构建的卷积神经网络进行识别。
所述4个卷积层、4个池化层和2个全连接层的卷积神经网络具体为:
layer1为卷积层,采用64个3×3的卷积核对输入图像做卷积,输出64个64×64的特征图像;
layer2为池化层,输入layer1的输出图像,池化窗口大小为2×2,步长设为2×2,选择填充方式为same,故64个大小为64×64的图像,经layer2计算后输出为64个大小为32×32的特征图像;
layer3为卷积层,采用128个3×3的卷积核对layer2的输出图像做卷积,输出是128个大小为32×32的特征图像;
layer4为池化层,输入为layer3的输出图像,池化窗口大小为2×2,步长设为2×2,选择填充方式为same,故128个大小为32×32的图像,经layer4计算后输出为128个大小为16×16的特征图像;
layer5为卷积层,采用256个3×3的卷积核对layer4的输出图像做卷积,输出是256个大小为16×16的特征图像;
layer6为池化层,输入为layer5的输出图像,池化窗口大小为2×2,步长设为2×2,选择padding方式为same,故256个大小为16×16的图像,经layer6计算后输出为256个大小为8×8的特征图像;
layer7为卷积层,采用512个3×3的卷积核对layer6的输出图像做卷积,输出是512个大小为8×8的特征图像;
layer8为池化层,输入为layer7的输出图像,池化窗口大小为2×2,步长设为2×2,选择padding方式为same;经layer8计算后输出为512个大小为4×4的特征图像;
layer9为全连接层,输入为上一层的输出图像,输出为1024个神经元,在进入下一层之前,再次做dropout处理,dropout率仍为0.8;
layer10为全连接层,输入为layer9的输出,输出为3755个神经元,用于执行最终的识别。
进一步地,在layer8的输出图像进入下一个网络层之前,为防止网络模型过拟合,先对layer8的输出特征图像做dropout处理,dropout率设为0.8。
其中,4个池化层均采用最大池化计算。
本发明提供的技术方案的有益效果是:
1、本发明利用卷积神经网络技术,构建了一个10层的卷积神经网络,解决了传统手写中文识别准确率较低的问题;
2、本发明将直方图投影算法引入到单个中文识别技术中,突破了现有技术仅仅是单个中文层面上的识别技术,为大量纸媒文本的机器识别和电子化提供了新的方法;
3、本发明最终不仅在单个中文识别中取得了很高的准确率,在手写文本识别上也获得了较高的准确率,可用于识别文档、手写笔记等实际应用。
附图说明
图1是一种基于cnn的手写中文文本识别方法的流程图;
图2是待测的手写体文档i图像的示意图;
图3是切割后的单个文字图像的示意图;
图4是裁剪后的单个文字图像的示意图;
图5是文档i的识别结果的示意图;
图6是待测的手写体文档ii图像的示意图;
图7是文档ii的识别结果的示意图。
表1是hwdb数据集训练测试结果;
表2是对实际手写体文档i和ii的测试结果。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
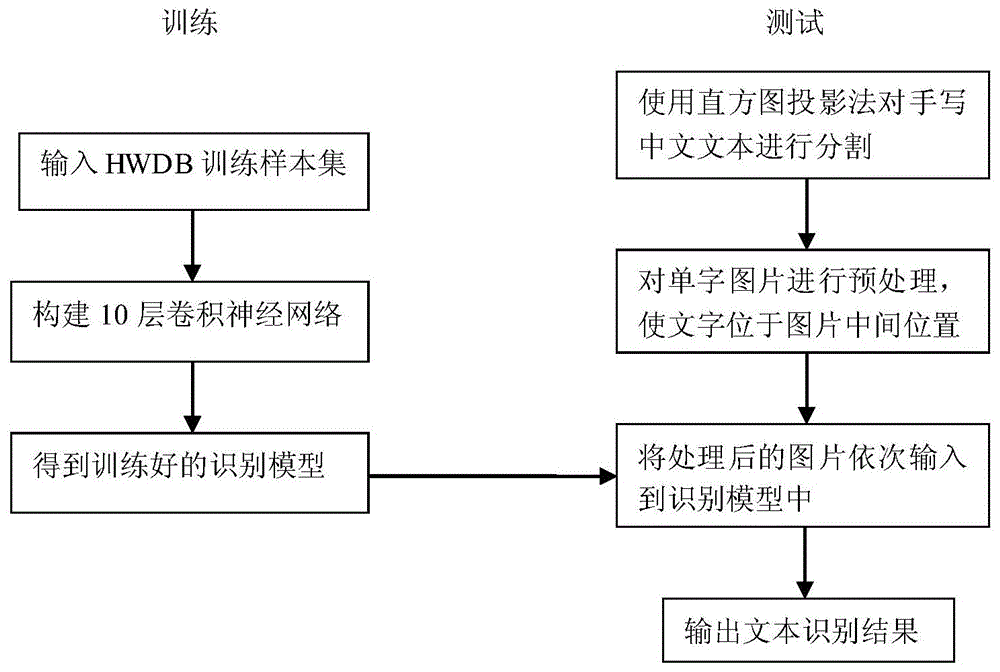
本发明实施例提供了一种基于cnn的手写中文文本识别方法,参见图1,该方法包括以下步骤:
101:对文本图片进行灰度化、二值化处理,再利用直方图投影[5,6]对中文文本进行分割;先通过横向扫描分割出单行文字,再利用纵向扫描分割出单个文字;
102:对单个中文图片进行扫描处理,对中文进行正射纠正,并使其位于图片中间位置,上下左右各留出10个空白像素;
103:构建卷积神经网络,利用训练集进行训练;输入待测图片,利用构建的卷积神经网络进行识别。
其中,本发明实施例基于tensorflow框架[7](该框架为本领域技术人员所公知)构造一个卷积神经网络,该卷积神经网络包括:4个卷积层、4个池化层和2个全连接层,整体架构为:
input-64c2-mp2-128c2-mp2-256c2-mp2-512c2-mp2-1024fc-output,网络的走向从左到右。4个池化层均采用最大池化计算,padding(填充)方式选择same[8](在输入input高和宽维度的周围添加像素点,当步长为1时,保证得到的新图与原图的形状相同)。最后一层池化层主要用于防止网络模型出现过拟合,通过对其进行dropout正则化处理,可加快训练速度。
在训练初期,由于距离极值点较远,本发明实施例将学习率设为一个较大值0.0002,以实现快速收敛;在训练后期,为避免在极值点附近波动,本发明实施例每训练2000次,将学习率乘以0.97,以实现学习率的动态调整,保证训练的稳定性。
具体实现时,输入图像是大小为64×64的灰度图,只有一个通道;
1、设layer1为卷积层,采用64个3×3的卷积核对输入图像做卷积,输出64个64×64的特征图像;
2、设layer2为池化层,输入layer1的输出图像,池化窗口大小为2×2,步长设为2×2,选择padding方式为same,故64个大小为64×64的图像,经layer2计算后输出为64个大小为32×32的特征图像;
3、设layer3为卷积层,采用128个3×3的卷积核对layer2的输出图像做卷积,输出是128个大小为32×32的特征图像;
4、设layer4为池化层,输入为layer3的输出图像,池化窗口大小为2×2,步长设为2×2,选择padding方式为same,故128个大小为32×32的图像,经layer4计算后输出为128个大小为16×16的特征图像;
5、设layer5为卷积层,采用256个3×3的卷积核对layer4的输出图像做卷积,输出是256个大小为16×16的特征图像;
6、设layer6为池化层,输入为layer5的输出图像,池化窗口大小为2×2,步长设为2×2,选择padding方式为same,故256个大小为16×16的图像,经layer6计算后输出为256个大小为8×8的特征图像;
7、设layer7为卷积层,采用512个3×3的卷积核对layer6的输出图像做卷积,输出是512个大小为8×8的特征图像;
8、设layer8为池化层,输入为layer7的输出图像,池化窗口大小为2×2,步长设为2×2,选择padding方式为same。
因此,512个大小为8×8的图像,经layer8计算后输出为512个大小为4×4的特征图像。在layer8的输出图像进入下一个网络层之前,为防止网络模型过拟合,先对其做dropout处理,dropout率设为0.8;
9、设layer9为全连接层,输入为上一层的输出图像,输出为1024个神经元,同理,在进入下一层之前,再次做dropout处理,dropout率仍为0.8。
10、设layer10为全连接层,输入为layer9的输出,输出为3755个神经元,用于执行最终的识别。
综上所述,本发明实施例解决了传统手写中文识别准确率较低的问题,并将单个手写中文识别与文字分割算法结合起来,实现了手写中文文本的自动识别。
实施例2
下面结合具体的计算公式、实例对实施例1中的方案进行进一步地介绍,详见下文描述:
201:对图像进行二值化处理,对二值化图像作水平方向投影,并计算像素,获得水平方向的投影曲线;
其中,投影曲线中的部分零值代表文本行之间的空白区域,以零值中心水平线对文本图像进行分割,提取出每行文字。
202:利用步骤201得到的水平方向的投影曲线对二值化图像作行切割,然后对切割后的每一行图像作垂直方向的投影,获得垂直方向的投影曲线;
具体实现时,由于手写体文字之间可能存在连笔情况,因此垂直方向的投影曲线中两个字符之间往往不为零,本发明实施例以两个波峰间的峰谷作为分界线,实现单个字符的自动分割。
203:利用步骤201和步骤202得到水平方向的投影曲线以及垂直方向的投影曲线确定坐标,分割出单个文字图像;
204:对单个文字图像进行裁剪处理,使得文字处于图片中间位置,上下左右各自余留10个像素的空白区域;
205:构建卷积神经网络(cnn),并对数据集进行训练;
其中,训练数据集采用模式识别国家重点实验室的hwdb(handwritingdatabase,笔迹数据库)数据集,包括3755个中文,其中每个中文有约300张不同字迹;整个数据集以4:1的比例分为两部分,任选80%的数据作为训练数据集,剩下20%数据作为测试数据集,用于评判训练模型的准确性。
在一定范围内,增加输入字符图像的大小可以提高分类性能,但会增加计算成本;经过测试发现,将输入字符的大小调整为64×64时效果最优,可实现二者之间的有效平衡。
206:分别读取训练集和测试集的图片信息和标签信息,并作归一化处理,将其作为输入层,输入到构建的卷积神经网络中。
针对卷积计算,padding(填充)方式选择same。经same处理大小为n×n的图像卷积之后大小为:n2/s2,其中,f×f表示卷积核大小,s表示步长。
layer1为卷积层,卷积核个数为64,高度宽度为3×3,步长为1,选择padding方式为same;因此,大小为64×64的图像经layer1计算后输出仍为64个64×64的特征图像。
layer2为池化层,输入为layer1的输出,池化窗口大小为2×2,步长为2×2,选择padding方式为same;因此,64个大小为64×64的图像经layer2计算后输出为64个大小为32×32的特征图。
layer3为卷积层,卷积核个数为128,高度宽度为3×3,步长为1,选择padding方式为same;因此,大小为32×32的图像经layer3计算后输出为128个32×32的特征图像。
layer4为池化层,输入为layer3的输出,池化窗口大小为2×2,步长为2×2,选择padding方式为same;因此,128个大小为32×32的图像经layer4计算后输出为128个大小为16×16的特征图。
layer5为卷积层,卷积核个数为256,高度宽度为3×3,步长为1,选择padding方式为same;因此,大小为16×16的图像经layer5计算后输出为256个16×16的特征图像。
layer6为池化层,输入为layer5的输出,池化窗口大小为2×2,步长为2×2,选择padding方式为same;因此,256个大小为16×16的图像经layer6计算后输出为256个大小为8×8的特征图。
layer7为卷积层,卷积核个数为512,高度宽度为3×3,步长为1,选择padding方式为same;因此,大小为8×8的图像经layer7计算后输出为512个8×8的特征图像。
layer8为池化层,输入为layer7的输出,池化窗口大小为2×2,步长为2×2,选择padding方式为same;因此,512个大小为8×8的图像经layer8计算后输出为512个大小为4×4的特征图。
在layer8的输出图像进入下一个网络层之前,为防止网络模型过拟合,先对其做dropout处理。经过多次测试结果,本发明实施例中dropout率定为0.8。
dropout是一种应用在深度学习环境中的正规化方法,指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于将原始网络进行一次裁剪。其工作原理是:在一次循环中先随机选择神经层中的一些单元并将其临时隐藏,然后再进行该次循环中剩余神经网络的训练和优化。在下一次循环中,又将隐藏另外一些神经元,如此反复,直至训练结束。
没有dropout的神经网络计算公式:
有dropout的神经网络计算公式:
其中,p是bernoulli分布中值为1的概率,w是权重,b是偏置,l是层数,i是当前层的神经元数,z、r是中间变量,y是输出值,是经过dropout正则化的输出值,f是激活函数,本发明实施例中使用tanh函数做激活函数,计算公式如下:
tanh(x)=(1-e-2x)/(1+e-2x)(7)
在训练阶段,每个神经单元被保留的概率为p;在测试阶段,每个神经单元都存在的,权重参数为pw。
layer9为全连接层,输入为上一层的输出图像,输出为1024个神经元。同理,在进入下一层之前,再次做dropout处理,dropout率仍为0.8。
layer10为全连接层,输入为layer9的输出,输出为3755个神经元,表示3755个中文,用于执行最终识别。
损失函数使用softmax交叉熵函数[8](见公式8),将上一层的输出值与输入的真实标签对比计算出损失再归一化为概率值,之后再求均值。
假设在进入softmax函数之前,已经有模型输出c值,其中c是要预测的类别数,模型可以是全连接网络的输出a,其输出个数为c,即输出为a1,a2,...,ac;因此对于每个样本,它属于类别i的概率为:
通过上式可以保证即属于各个类别的概率和为1。本发明实施例中c值为3755,即中文识别的总字符个数。
利用argmax函数[8]找出预测出的标签与输入的真实标签进行对比,可以计算出预测的平均准确率。学习率进行动态调整,初始学习率为0.0002,每次迭代步数为2000,衰减比例为0.97。
其中,上述优化算法采用adamoptimizer算法[8],促进超参数动态调整。
207:得到训练好的模型后,将分割并处理后的单个中文输入模型进行识别,得到识别好的中文文本结果。
综上所述,本发明实施例解决了传统手写中文识别准确率较低的问题,并将单个手写中文识别与文字分割算法结合起来,实现了手写中文文本的自动识别。
实施例3
下面结合图2-图7、表1及表2对实施例1和2中的方案进行可行性验证,详见下文描述:
301:本发明实施例利用softmax交叉熵函数计算损失函数,将上一层的输出值与输入的真实标签进行对比,计算损失并将其归一化为概率值,再求均值;利用argmax函数找出预测出的标签,通过与输入的真实标签进行对比,计算出预测的平均准确率;动态地调整学习率,初始学习率设为0.0002,每次迭代步数为2000,衰减比例为0.97。采用adamoptimizer优化算法促进参数动态调整。
302:首先利用构建好的卷积神经网络对hwdb数据集进行训练和测试,并得到训练好的模型。
其中,训练样本约901200个,测试样本为225300个。表1是hwdb数据集训练测试结果。top_1(概率最高者为正确识别)的准确率为92.4821%,top_3(概率最高的3个中包括正确识别)的准确率高达97.4861%,这一结果已高于人类表现96.1%。
303:实验结果的分析。
图2是待测的手写体文档i图像的示意图,先对其进行灰度化、二值化处理,再利用直方图投影技术对其进行分割,得到197张单个字符图片。图3是切割后的单个中文“你”的示意图,可以看出,文字在图片中的位置不均匀,上下空白较多,左右紧贴边缘,如果直接进行识别,错误率可能会很高。因此对其进行处理,在裁剪完四周多余空白后又各自填充了空白部分使得文字位于图片中间位置,图4是裁剪后的单个中文“你”的示意图。197张图片处理完后依次输入训练好的模型中进行识别,图5是文档i的识别结果的示意图。其中,197个中文正确识别了190个,识别错误7个,错误识别中,如:“需”和“雷”、“手”和“车”等字都是因为手写体字形过于相似所导致;以后可以针对这些易混淆的中文增加训练集,重新进行训练,以进一步提高模型的准确性。
304:图6是待测的手写体文档ii图像的示意图,对其进行识别,步骤同文档i。
图7是文档ii的识别结果的示意图,图中共有198个中文,正确识别196个,识别错误2个,错误识别中,“人”和“久”、“手”和“寺”也是因为手写体字形过于相似所导致。结合文档i可以发现:识别错误的重复率很高,因此以后可以针对这些形近字来增加训练集,以继续优化模型。
305:表2是对实际手写体文档i和ii的测试结果,可以看出,两个手写体文档的识别准确率都高达96%以上。
表1hwdb数据集训练测试结果
表2实际手写体文档测试结果
参考文献
[1]kimuraf,takashinak,tsuruokas,etal.modifiedquadraticdiscriminantfunctionsandtheapplicationtochinesecharacterrecognition[j].ieeetranspatternanalmachintell,1987,pami-9(1):149-153.
[2]g.e.hinton,n.srivastava,a.krizhevsky,etal.improvingneuralnetworksbypreventingco-adaptationoffeaturedetectors.arxivpreprintarxiv:1207.0580,2012.
[3]a.krizhevsky,1.sutskeverandg.e.hinton.imagenetclassifcationwithdeepconvolutionalneuralnetworks.advancesinneuralinformationprocessingsystems,1097-1105,2012.
[4]f.yin,qf.wang,xy.zhang,c.l.liu,icdar2013chinesehandwritingrecognitioncompetition,icdar2013.
[5]王莉丽,于印.一种基于双向投影的文本图像字符分割方法[j].数字技术与应用,2017(5):74-75.
[6]路敬祎,薛征,邵克勇,etal.基于改进的连通域算法与垂直投影相结合的车牌字符分割[j].自动化技术与应用,2015,34(12):93-97.
[7]abadi,martín,barhamp,chenj,etal.tensorflow:asystemforlarge-scalemachinelearning[j].2016.
[8]tensorflowapidocumentation[m].google,2015.
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!